See on Scoop.it – Moodlicious
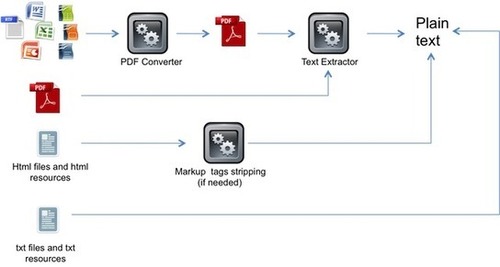
Moodle text cloud block basically performs the following operations:
On each cron cycle, the block search for new resources included in the course. If new resources are found, it process the resource for indexing
The indexing process distinguishes between different resources types. MS Office and Open Document Format documents are converted into PDF format by the Unoconv application [2]. PDF files are converted into PlainText Files. HTML files are converted into Text files via a specific function that removes HTML tags and other formatting text.
Text of PlainText files is extracted, and processed for text analysis. This involves further steps: a) Language detection; b) stop-words filtering; c) stemming algorithm application.
Last step consists on calculating frequencies and other statistics to determine the weight of every tag.
Moodle text cloud block is able to work with different languages. The current version comes with 11 analysis languages (danish, dutch, english, french, german, italian, norwegian, polish, portuguese, spanish and swedish), 4 of these (english, german, italian and spanish) contains also the stemming engine. New language analyser and stemming engine can be added very easily.


